统计学家会让作家失业吗?
 2021-07-17
2021-07-17

在周五的愚公子专栏,经常有读者在评论区愉快地猜测愚公子是男生还是女生,因为喜欢博主进而好奇地猜测博主性别的事情并不鲜见,但由此能反映我们的大脑其实天然地具备统计学思维,总会不知不觉地根据看到某些文或图的概率,尝试归纳一些特点。
如果说日常生活中人们只是凭感觉统计,那么统计学家就能无限发挥他们的计算能力,而这也产生了一门交叉学科,叫Digital Humanities(数字人文学):用统计学探究人文学。在《欢乐数学》这本书中,作者结合自己的“烂插画”轻松描述了这门学科的特点。这位作者是知名博主,当然,他也带着好奇收集自己的文章,用统计的方法测试了自己在别人眼中的性别。
好玩归好玩,作者对于统计学能把文学作品“吃透”感到担忧,但他也利用统计学得出来的结论完善了自己的这本书。所以统计技术能与更古老、更丰富、更人性化的语言理解方式和谐相处吗?
下文摘编整理自《欢乐数学:一本充满“烂插画”的快乐数学启蒙书》,经出版社授权刊发。内容有删减,小标题为摘编者所加。
原文作者 | [美] 本·奥尔林
摘编|王一

《欢乐数学》,[美]本·奥尔林 著 唐燕池 译,未读 | 天津科学技术出版社 2021年6月版(点击封面可购买)
01
一头叫作数字人文学的怪兽
生命的图书馆里有一头叫作数字人文学(Digital Humanities)的怪兽,它拥有文学评论家的身体、统计学家的头脑,以及心理学家史蒂芬·平克(Seven Pinker)的一头乱发。有些人把它当作射入黑暗洞穴的一束光,并为之欢呼;而另一些人则把它视为流着口水啃着第一版《包法利夫人》的狗,对它不屑一顾。所以,这只怪兽是做什么的呢?
很简单:它将书籍转换成数据集。
去年,我读了本·布拉特(Ben Blatt)的著作《纳博科夫最喜欢的词》,这本令人愉悦的书通过统计技术分析了一些文学领域的伟大作家。第一章题为“简洁‘地’用词”,探讨了一个老生常谈的写作建议:少用副词。斯蒂芬·金曾经把副词比作杂草,并警告说:“通往地狱的道路是由副词铺成的。”因此,布拉特统计了不同作者的作品中以“-ly”结尾的副词使用频率(firmly“坚定地”,furiously“猛烈地”等),最后发现:
在1000个单词中以“-ly”结尾的副词出现次数
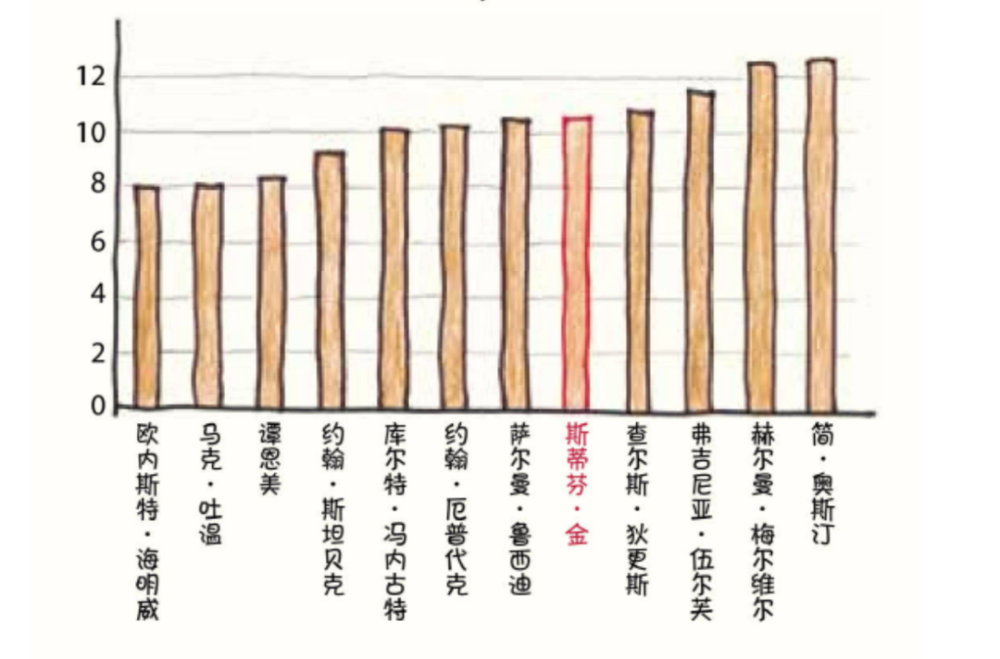
作为英国最杰出的小说家之一,简·奥斯汀对副词的友好态度似乎充分驳斥了这一观点。但是布拉特指出了一个有趣的规律,在同一个作家的作品中,最伟大的小说往往使用的副词最少。
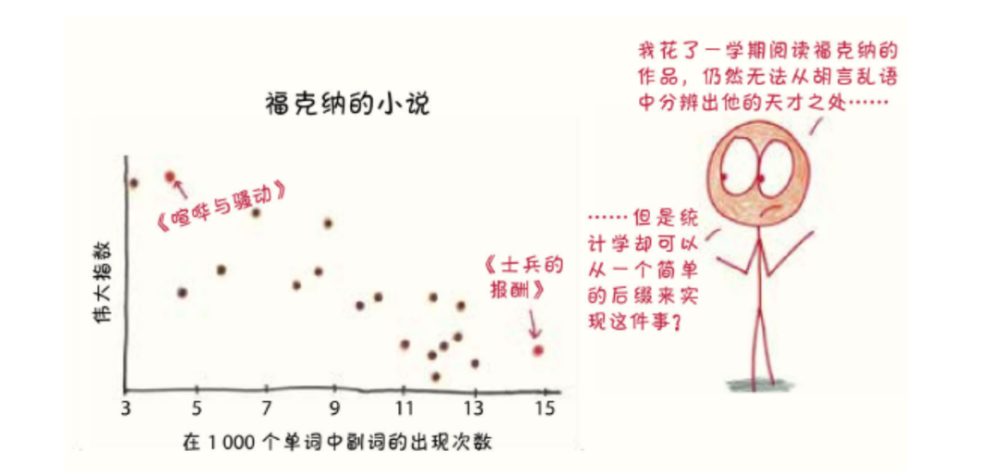
F.斯科特·菲茨杰拉德副词最少的小说是《了不起的盖茨比》;托妮·莫里森的是《宠儿》;查尔斯·狄更斯的是《双城记》,紧随其后的是《远大前程》。当然,也有例外——纳博科夫的《洛丽塔》可以说是他最受推崇的小说,而其中的副词频率达到巅峰。但趋势还是很明显的:低频使用副词让写作更清晰有力,而高频使用副词暗示了内容和节奏不够紧凑。
我想起了大学里的一天,我的室友尼尔什笑着对我说:“你知道我最喜欢你什么吗?就是你非常爱用‘可想而知’(conceivably)这个词,这是你的口头禅之一。”
我愣住了,进行了反省。而从那一刻起,“可想而知”这个词从我的字典里消失了。
尼尔什为这个词的消失难过了好几个月,而我同时背叛了两个朋友——这个单词和我的室友。我实在无能为力。原本我脑海中那个将意义转化为文字的幽灵是靠本能在工作的,它在阴影中自在地茁壮成长,而当我们把注意力集中到一个特定词的选择上时,会使这个幽灵感到害怕,它便退缩了,再也不用这个词了。
看了布拉特的统计数据后,这种情况再次发生了。我得了副词妄想症。从那以后,我写作的时候就像一个不安的逃亡者,害怕那些以“-ly”结尾的副词会像蜘蛛爬进熟睡时的我嘴里那样溜进我的散文中。我认识到,这是一种生硬的、人为的语言研究方法,更不用说其中幼稚的“相关性等于因果关系”的统计方法了。但是我没办法。简单来说,这就是数字人文学科的希望和危险;而就我而言,重点在于“简单”。
文学作为词的集合,是一个异常丰富的数据集。反之,如果仅仅作为一个词的集合,文学就不再是文学。统计在运作时会排除上下文,它对洞察力的探索始于意义的消失。作为一个统计爱好者,我被吸引了;而作为一个爱书的人,我却退缩了。丰富的文学语境和冰冷的统计分析之间,能否有和平共处的方式?还是像我担心的那样,它们就是宿敌?
02
统计学家做的文化研究
2010年,以让-巴蒂斯特·米歇尔(Jean-Baptiste Michel)和埃雷兹·利伯曼·艾登(Erez Lieberman Aiden)为首的14位科学家发表了一篇轰动全球的研究文章,文章题为《通过数百万本数字化书籍对文化进行的定量分析》(Quantitative Analysis of Culture Using Millions of digital Books)。每当我读到它的开场白时,我都情不自禁地感叹一声“我的天哪”。它的开头是:“我们构建了数字化文本的语料库,其中包含的书占世界上印刷图书总数的4%。”
我的天哪!
与所有统计学研究项目一样,这个研究需要大刀阔斧地简化。文章作者做的第一件事就是将整个数据集——500万本书,总计5000亿个单词——都分解成他们所谓的“1-gram”。他们解释道:“一个1-gram就是一串中间没有空格的字符,包括单词(‘banana’ ‘SCUBA’),也包括数字(‘3.14159’)和错别字(‘excesss’)。”
句子,段落,论点——它们统统消失了,只剩下一个个文本的碎片。
为了探测数据的深度,研究人员汇总了频率为十亿分之一以上的1-gram。从20世纪初期到中期再到末期,他们可以从语料库看出语言的不断发展:
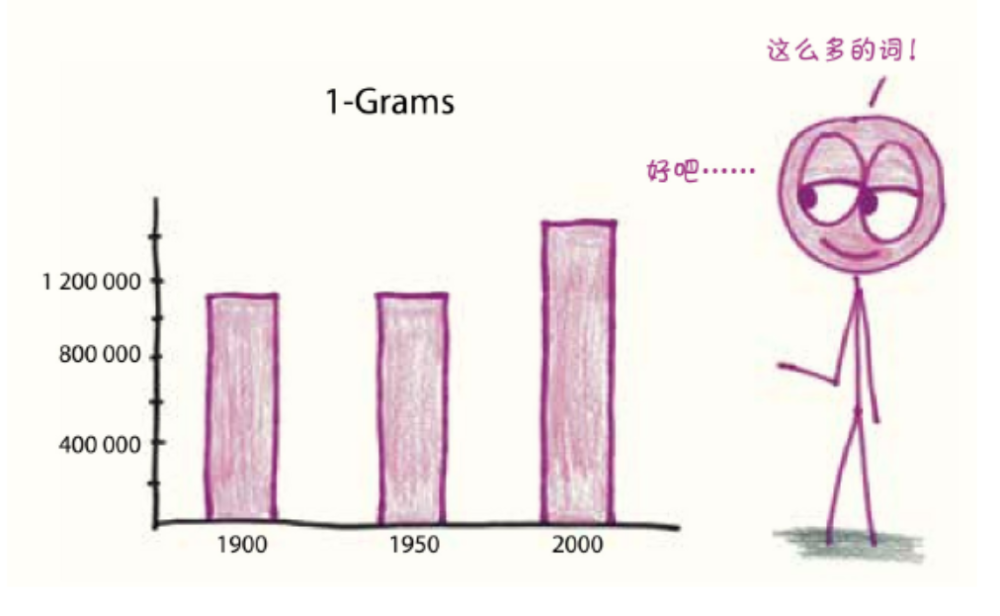
在研究了数据后发现,1900年的1-gram中只有不到一半是真正的单词(不属于数字、拼写错误、缩写等),而2000年的1-gram中有超过三分之二是真正的单词。从统计的样本中,研究者估算出了每年英语单词的总数:
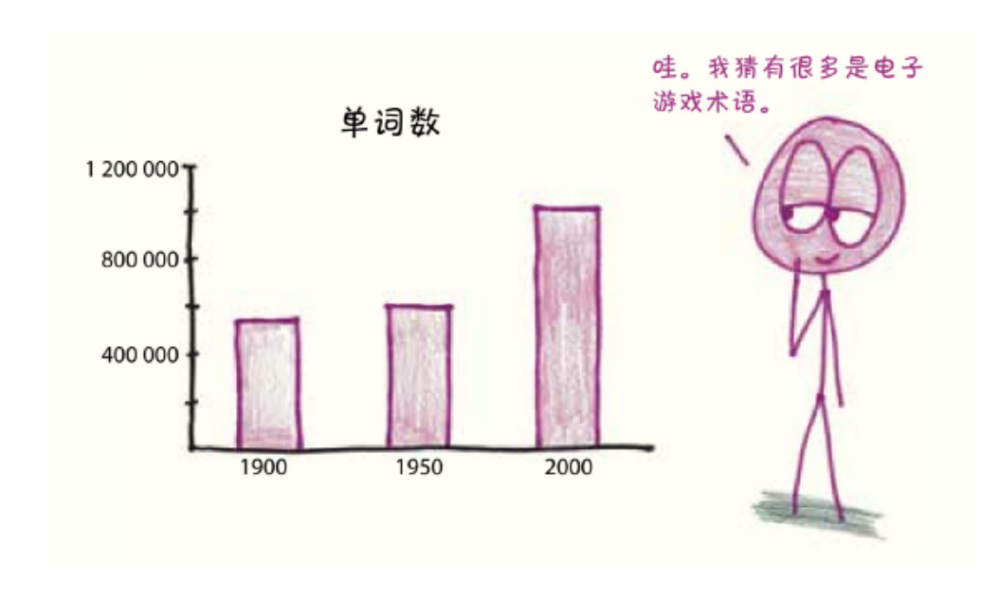
接着,他们在两本常用的词典中查找了这些1-gram,发现词典编纂者正在努力跟上语言的发展步伐。尤其值得一提的是,这些词典没有收录大多数罕见的1-gram单词:
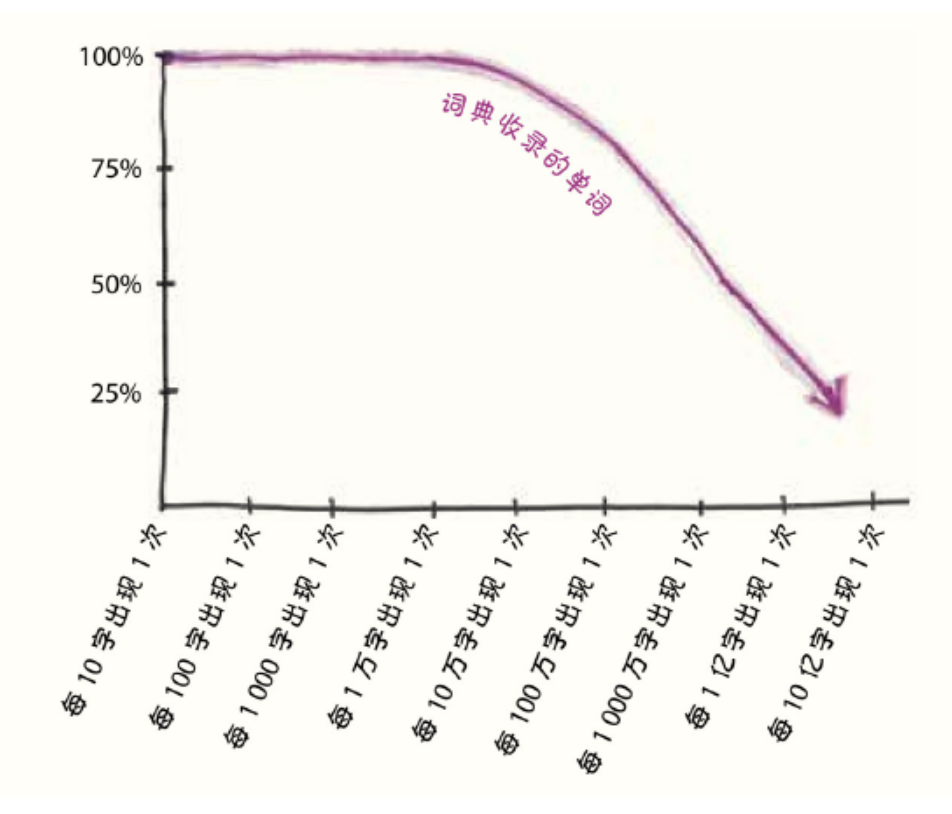
我在平时的阅读中,并没有遇到很多罕见的、词典中没有收录的词汇。那是因为……嗯……它们确实很罕见。然而,语言中充斥着大量默默无闻的、出现频率低于一亿分之一的单词。总的来说,作者估计“52%的英语词汇,也就是英文书中使用的大多数单词,都是由标准参考文献中没有记载的‘暗物质’词汇组成”。这些词典只触及了皮毛,漏掉了像“slenthem”(一种金属制作的乐器)这样的珍宝词汇。
对这些研究人员来说,在词汇中的探险还只是热身。接下来,作者们通过跟踪筛选的1-gram频率研究了语法的演变、作家成名的轨迹、审查制度的印记和历史记载的转变模式。所有这些只用了十几页就完成了。
这篇文章让我惊掉了下巴。《科学》杂志察觉了这一研究的重要意义,免费向非订阅客户开放这篇文章。《纽约时报》宣称:“这是一扇崭新的文化之窗。”
文学学者倾向于研究独特的“经典”,只有少数精英作家能被深入、专注地分析。比如托妮·莫里森和詹姆斯·乔伊斯,还有坐在乔伊斯的键盘上敲下了《芬尼根的守灵夜》(Finnegans Wake)的那只猫。但这篇论文指向的是另一种模式:一个包罗万象的“语料库”,在这个语料库中,无论是知名的还是无名的图书,都同样获得研究者的注意。统计数据是推翻文学的寡头制、建立起民主政体的有力工具。
理论上,精读和正典与统计学和语料库,这两种模式并没有无法共存的理由。尽管如此,像“精确测量”这样的短语还是指出了一种冲突。文学的意义能“精确”吗?它们可以被描述为“可测量的”吗?或者说,这些强大的新工具会带领我们离开难以量化的艺术深处,去寻找我们的锤子能打到的钉子吗?
03
统计学能算出我的性别吗?
在我来看,散文应该是没有性别的。我的散文像雌雄同体的海绵;弗吉尼亚·伍尔芙的散文则像银河或神的启示。但伍尔芙在《一间自己的房间》表达了相反的观点,她认为早在1800年,流行的文学风格就已经演变成男人思想的容器,容纳不了女人的思想。散文的节奏和形式本身就带有某些性别特征。
这个观点在我脑海里萦绕了几个月,直到我在网上看到一个叫“魔幻酱汁(Apply Magic Sauce)的项目,它可以阅读你复制粘贴上去的文章节选,并通过神秘的分析方法预测作者的性别。
这太有意思了,我必须试试。

在眼花缭乱的博客网站上,我花了一个小时复制粘贴了25篇博客文章,这些文章写于2013年至2015年。最终的结果是这样的:
分辨我博客的性别
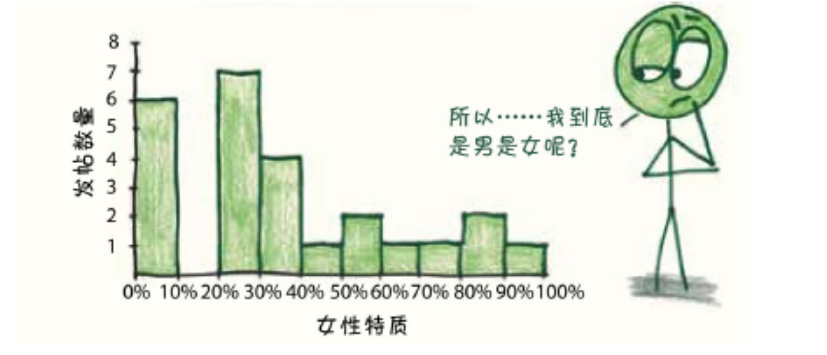
由于“魔幻酱汁”团队对技术是保密的,我开始试图探究这个算法可能的运行模式。它是用图表绘出了我的文章片段吗?它嗅出了我情感中潜在的男权主义吗?它是否像我想象中的弗吉尼亚·伍尔芙那样,渗透到我的思想中,把阅读图书上升为一种阅读灵魂的形式?
不,它很可能只是观察单词的频率。
在2001年发表的一篇名为《按作者性别对文字自动进行分类》(Automatic Categorizing writing text by Author Gender)的论文中,三位研究人员仅通过计算几个简单单词的出现次数,就成功地将男性和女性作家区分开来,准确率达到80%。后来的一篇题为《正式书面文本中的性别、体裁和写作风格》(Gender, Genre, and Writing Style in Formal Written Texts)的论文用通俗易懂的语言阐述了这些差异。一方面,男性更多地倾向于使用名词限定词(“一个”“这”“一些”“大多”……);另一方面,女性更喜欢使用代词(“我”“他自己”“我们的”“他们”……)。
非虚构类作品中的单词类型
事实上,甚至连“你”这个平平无奇的单词出现的频率都能透露出作者的性别:
虚构类作品中“你”一词的使用
这个数据系统如此简洁,让人们更惊讶于它的准确性。这种方法忽略了所有的上下文、所有的句意,只关注非常小的一部分单词的选择。正如布拉特所指出的那样,它会把“这句话是女人写的”这句话评价为更有可能是男人写的。
然而,如果你把视野扩大到所有的单词,而不仅仅是语法上的小连接词,那么结果就会转向刻板印象。一家名为CrowdFlower的数据公司研究出一种用于推断社交网络账户所有者性别的算法,它选出了以下性别预测词汇:
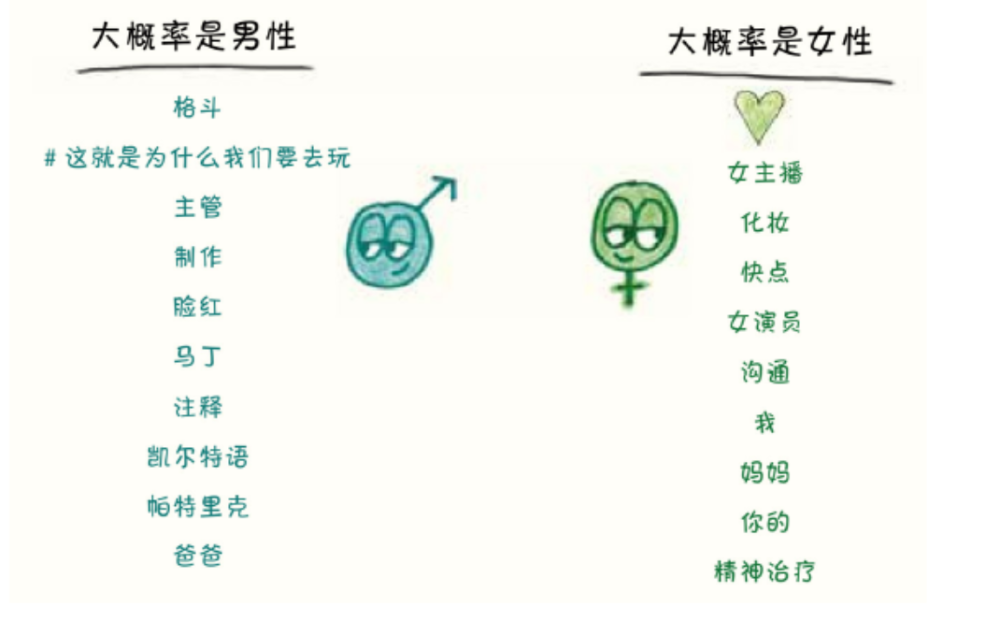
而在《纳博科夫最喜欢的词》中,本·布拉特发现经典文学中最具有性别特征的词是:

“魔幻酱汁”看起来也依靠了这些线索。当数学家凯茜·奥尼尔使用“魔幻酱汁”的算法测试一名男性写的关于时尚的文章时,结果为99%女性特质。当她测试一名女性写的关于数学的文章时,结果是99%男性特质。而奥尼尔自己的三篇文章则分别获得了99%、94%和99%的男性特质评分。”这是个小范围的测试,”她写道,“但我打赌,这个模型代表了一种刻板印象,根据作者选择的主题来确定作者的性别。”
这些结果不准确的例子并没有平复我内心的恐惧。我的男性特质似乎已经渗透到我的思维中,以至于一种算法可以用两种不重叠的方式将它检测出来:其一是我对代词的使用情况;其二是我对欧几里得的喜爱。
我知道,这在某种程度上证明了伍尔芙是对的。她发现了男人和女人正经历着不同的世界,并相信女权的斗争必须从句子的层面开始。粗糙的统计数据也证实了这一点:女性写作的话题和方式与男性不同。
不过,我还是觉得这一切都有点儿令人沮丧。如果说伍尔芙的写作揭示了她的女性特质,我更愿意认为这些女性特质嵌入了她的智慧和幽默之中,而不是通过她使用名词限定词的频率较低表现出来的。听伍尔芙分辨男性和女性的散文,感觉像是去看一位值得信赖的医生,而如果让算法做同样的事,就让人感觉像在机场被搜身一样。
04
统计数据和文学意义能否共存?
2011年,斯坦福大学文学实验室的学者尝试了一个棘手的跃进试验:从识别文章作者到识别文章体裁。他们使用了两种方法:词频分析和一种更复杂的句子层面的工具(称为Docuscope)。出人意料的是,这两种方法都能进行准确的体裁判断。
我有些不安,算法比我知道的多太多了。
令我稍感宽慰的是,研究人员给出了一个试探性的结论:没有一个单一的元素可以区分一个作家或流派,也没有一个独有的特征可以让所有其他作家效仿。相反,写作中的特征包括很多方面,从小说的总体结构一直延伸到分子般的音节结构。而统计数据和文学意义是可以在相同的单词序列中共存的。
大多数时候,我是为了建造一个自己的世界而阅读,书中有情节、主题、人物——这是一种高层次的结构,是任何路人都能看到,但统计数据却无法解释的层面。
如果看得再近一些,我就可以看到这个建筑的一砖一瓦,包括句子、句子结构、段落的设计。这是我的高中英语老师教我观察的微观结构,计算机也能学会做同样的事。
而在这之下还隐藏着砂浆,包括代词、介词、不定冠词。这些纳米级结构对我的眼睛来说太精细了,但对于统计学家的化学分析来说却是理想的研究对象。
虽然这只是一个比喻,但这个比喻是我大脑中冥冥响起的声音。我头脑一热,便打开这本书的第一部分(“如何像数学家一样思考”),对以“-ly”结尾的副词频率进行了统计,结果为每1000个单词中有10个,和弗吉尼亚·伍尔芙作品中以“-ly”结尾的副词频率差不多,这是一个好预兆。接下来,我忍不住删除了不必要的“-ly”副词,直到频率下降至每 1000个单词中8个以下,这是属于欧内斯特·海明威和托妮·莫里森的频率。我突然发现,作弊的感觉很棒。
新的统计技术真的能与更古老、更丰富、更人性化的语言理解方式和谐相处吗?是的,这是“可想而知”的。





